
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 백준
- 투포인터
- Algorithm
- 재귀
- Virtual Memory
- 재귀함수
- Github
- BF
- python3
- 신나는함수실행
- ML
- 브루트포스
- 알고리즘
- OS
- 백트래킹
- backtracking
- two pointer
- 완전탐색
- sort
- dfs
- Loss
- 1일1솔
- 코딩테스트
- 코테
- 프로그래머스
- Python
- 파이썬
- 정렬
- CS
- 머신러닝
- Today
- Total
이것저것 공부 기록하기
[DeepLearning] 추천시스템 metric 본문
추천시스템이란?
- 추천 시스템 : 아이템을 표현하는 다양한 방법(유저정보, 아이템 정보)
- 유저의 현 상황을 파악한 후 아이템을 추천하는 방법으로, 유저의 기호가 계속해서 변하는 것을 체크해야 함
- cold start problem 개선 연구 필요
- 데이터마다 고유한 특성이 존재(ex. 이미지: 픽셀, object, 언어: 문법 등)
- 추천 시스템에서 주로 사용하는 데이터의 형태

MovieLens dataset - categorical type 변수가 많아서 one hot encoding 된 데이터값이 많음
- one-hot vector 특성상 데이터 차원이 크고 매우 sparse 함
- 학습을 위한 label 생성 방법 다양
- Rating Matrix를 Matrix Factorization 을 통해 복원하는 방식 → Auto Encoder 계열 방식으로 접근
- Latent vector(유저, item)을 통해 matrix 곱으로 rating 값 자체를 맞추는 것(explicit feedback 존재할 경우)
- BPR(Bayesian Personalized Ranking) : negative sampling 을 통해 rating 값의 차이를 상대적으로 학습
- classification 을 통해 positive item의 값이 softmax 값이 높도록 학습
Metric
평가에는 여러가지 관점이 있을 수 있다. 비즈니스나 서비스 관점에서는 추천 모델의 정확도보다는 추천시스템을 적용함으로써 매출이나 클릭률(CTR)이 얼마나 증가하는가가 주요 관심사일 것이다.
품질 관점에서는 연관성이나 다양성, 새로움, 참신함 등을 기준으로 평가한다.
모델링을 하는 개발자의 관점에서 오프라인으로 테스트 시 사용하는 평가 지표도 있다. 우선 모델이 오프라인 테스트에서 좋은 성능을 보여야 온라인 테스트(A/B 테스트)를 진행할 수 있기 때문이다.
오프라인 테스트 시 사용하는 평가 지표는 크게 아래 두 가지 그룹으로 나눌 수 있다.
- Ranking 기반 추천시스템(Implicit feedback data) : Precision/Recall@K, NDCG@K, Hit Rate
- 평점 예측 기반 추천시스템(Explicit feedback data) : MAE, RMSE
1. Precision/Recall@K
기존의 Precision, Recall은 Binary classification에 사용되지만, 추천시스템은 하나의 아이템만 추천하지 않으며 정답도 여러 개가 될 수 있다. 따라서 추천 아이템 수를 의미하는 K를 함께 본다.

1) Precision@K
Precision : 기계가 1로 예측한 것 중에 실제 1이 얼마나 있는지 비율을 나타낸 것
Precision@K는 추천한 아이템 K개 중에 실제 사용자가 관심있는 아이템의 비율을 의미한다. 위 그림에서는 추천한 아이템은 5개, 추천한 아이템 중에서 사용자가 좋아한 아이템은 3개이므로 Precision@5=0.6 이 된다.
2) Recall@K
Recall : 실제 모든 1 중에서 기계가 1로 예측한 것이 얼마나 되는지 비율을 나타낸 것
Recall@K는 실제 사용자가 관심있는 모든 아이템 중에서 기계가 추천한 아이템 K개가 얼마나 포함되는지 비율을 의미한다. 위 그림에서는 사용자가 좋아한 모든 아이템이 6개, 그 중에서 기계의 추천에 포함되는 아이템이 3개이므로 Recall@5=0.5 가 된다.
2. Mean Average Precision@K
Precision@K, Recall@K는 모두 순서를 신경쓰지 않지만, 추천 시스템에서는 사용자가 관심을 더 많이 가질만한 아이템을 상위에 추천해주는 것이 매우 중요하다. 이를 위해 성능 평가에 순서 개념을 도입한 것이 Mean Average Precision@K 이다.
1) Average Precision@K
Precision@i : 추천한 아이템 개수 K중에서 해당 인덱스까지만 고려했을 때의 Precision 값. (ex. Precision@1은 가장 처음에 나오는 아이템을 하나만 추천했을 때의 Precision 값)
순서를 평가지표에 반영한 것이 AP. 사용자가 좋아한 아이템의 추천 순서가 높았는지 낮았는지에 따라 AP값이 크게 차이남. User A는 첫번째에 맞췄기 때문에 User B에 비해 점수가 훨씬 높다.
2) Mean Average Precision@K
MAP@K : 모든 유저에 대한 Average Precision@K의 평균
3. NDCG@K (Normalized Discounted Cumulative Gain)
NDCG : 원래 검색 분야에서 등장한 지표이나 추천 시스템에도 많이 사용되고 있음
Top K개 아이템을 추천하는 경우, 추천 순서에 가중치를 두어 평가하며, NDCG@K값은 1에 가까울수록 좋다. MAP는 사용자가 선호한 아이템이 추천 리스트 중 어떤 순서에 포함되었는지 여부에 대해서 1 또는 9으로만 구분하지만, NDCG@K는 순서별로 가중치 값(관련도, relevance)을 다르게 적용하여 계산한다.
- 가장 이상적인 추천 조합 대비 현재 모델의 추천 리스트가 얼마나 좋은지를 나타내는 지표
- 정규화를 통해 0~1 사이의 값 가짐
- DCG : K가 증가함에 따라 지속적으로 증가함
- NDCG : K에 어느 정도 독립적이어서 어떤 K가 적절한지 판단 가능
1) Relevance
- 사용자가 특정 아이템과 얼마나 관련이 있는지를 나타내는 값.
- 정해진 값이 아니며 추천의 상황에 맞게 정해야 함
- ex. 신발 추천 : 사용자가 해당 신발을 얼마나 클릭했는지, 또는 클릭 여부(binary) 등 다양한 방법으로 선정 가능
2) Cumulative Gain (CG)
- 추천한 아이템의 Relevance 합
- 두 추천 모델이 순서에 관계없이 동일한 아이템 셋을 추천한 경우 두 모델의 CG는 같아짐. 즉, 순서를 고려하지 않은 값
3) Discounted Cumulative Gain (DCG)
- CG에 순서에 따른 할인 개념을 도입한 것
- 추천 아이템의 순서가 뒤에 있을수록 분모가 커짐으로써 전체 DCG에 영향을 적게 주도록 함
- 사용자별로 추천 아이템의 수가 다른 경우 정확한 성능 평가가 어렵다는 한계 존재
- ex. 쇼핑몰에서 클릭한 신발 수가 5개인 사용자와 50개인 사용자에게 추천되는 아이템의 수는 다름
- 추천 아이템의 수가 많아질수록 DCG값은 증가하기 때문에 정확한 평가를 위해서는 Scale을 맞추어야 함
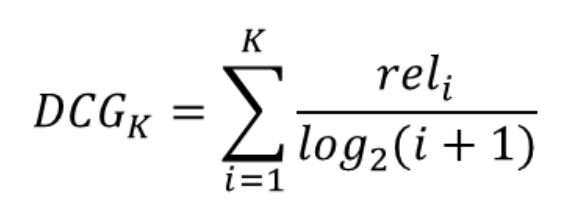
4) Normalized DCG (NDCG)
- DCG의 한계점을 보완하기 위해 DCG에 정규화를 적용한 것
- 정규화를 위해 DCG를 IDCG로 나눔
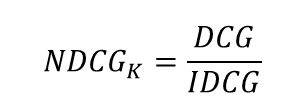
- cf. IDCG (Ideal DCG)
- 최선의 추천을 했을 때 받는 DCG값
- 모든 추천 아이템 조합 중, 최대 DCG값과 동일
- Relevance가 높은 순서대로 k개를 추천해주는 것이 이상적
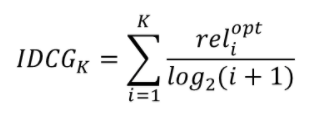
4. Hit Rate@K
Hit Rate : 적중률. 전체 사용자 수 대비 적중한 사용자 수를 의미한다.
Hit Rate는 4단계로 구할 수 있다.
- 사용자가 선호한 아이템 중 1개를 제외
- 나머지 아이템들로 추천 시스템을 학습
- 사용자별로 K개의 아이템을 추천하고, 앞서 제외한 아이템이 포함되면 Hit
- 전체 사용자 수 대비 Hit한 사용자 수 비율을 구하면 Hit Rate
5. MAE & RMSE
- MAE와 RMSE는 '평점 예측'에 대한 평가 방법
- 사용자별 아이템에 대한 정답 평점과 예측 평점이 있을 때 두 평점 간 차이를 바탕으로 성능을 평가하는 방법
1) MAE (Mean Absolute Error)
MAE : 정답 평점과 예측 평점 간 절대 오차에 대해서 평균을 낸 것
MAE는 직관적이고 해석이 용이하다는 장점이 있으나, 오차가 큰 이상치에 쉽게 영향을 받는다는 단점이 있다.
2) RMSE (Root Mean Square Error)
RMSE : 오차 제곱의 평균을 내고 루트를 취한 것.
MSE(Mean Squared Error)는 제곱으로 인해 단위가 커지는데, 루트를 씌움으로써 실체 예측값과 유사한 단위를 갖도록 만든다. 또한, MSE는 제곱을 하기 때문에, 1 미만인 오차는 더 작아지고 그 이상의 잔차는 더 크게 반영된다. 따라서 오차의 왜곡현상이 발생하는데, 루트를 통해서 이러한 현상을 완화시켜준다.
6. AUC
예측값과 실제 클릭 여부의 차이를 측정하는 메트릭이 아닌, 클릭 확률로 줄을 세웠을 때, 클릭한 아이템이 클릭하지 않은 아이템보다 상위에 랭크될 확률을 계산
7. Pointwise Loss
- 랭킹 자체를 최적화하기보다는, 아이템 한 개와 관련된 Loss의 최적화를 통해 랭킹 메트릭의 최적화
- 특정 아이템에 대해 예측한 값이 실제 값과 얼마나 다른지를 Loss로 정의하고, 그 Loss를 최소화하는 방식으로 작동
References
'DeepLearning' 카테고리의 다른 글
| [Deep Learning] Forward propagation (0) | 2022.09.12 |
|---|---|
| [DeepLearning] 추천시스템 모델 - Factorization (0) | 2022.01.08 |
